Why is estimating the effort necessary for a software development project so much more complicated than estimating the construction of a building? Because a software development project is a new project with mostly new people and often new technology for every new project.
Once again I had to experience that the estimation for a project was too optimistic. It is easy to estimate the expectable effort if yourself will be the person who has to realise the project. I remember that all estimations I did for myself where exact.
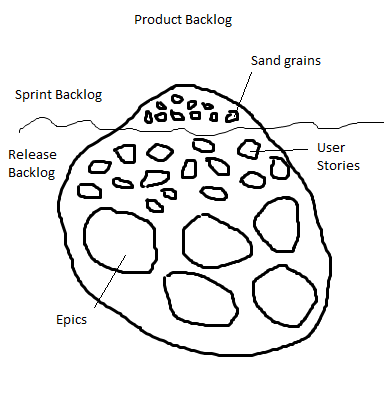
But as soon as the project is larger and is about a new business area, you have to do more work. You will have to do different kinds of estimations, for example a SCRUM story point estimation, a comparison with a similar project, a function point analysis and so on.
Now, there is the cone of uncertainty which tells us that an estimation done before the projects requirements were investigated properly could be far far away from the real effort you will spend. And the estimation will only come down to a more realistic value if you do another estimation after the requirements are clearer or even after you have started developing.